AI Can Already Exploit Your Smart Contract for $1.22. That Number Is Falling.
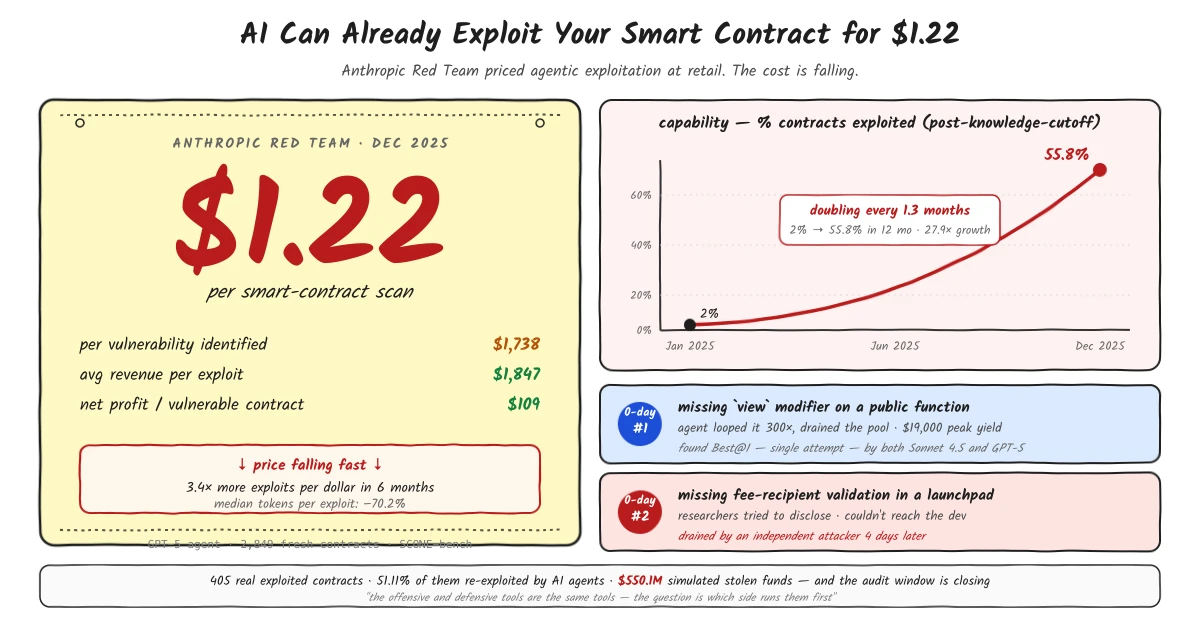
Anthropic's red team priced agentic exploitation at retail: $1.22 to scan, $1,738 per vulnerability identified, $109 net profit. AI agents went from 2% to 55.8% exploit success in 12 months. Two live zero-days found Best@1. The audit window is closing.
In December 2025, Anthropic’s red team published the most concrete pricing of AI-driven blockchain exploitation anyone has produced. Not attack success rates. Not theoretical risk frameworks. Dollar figures.
The number that matters: it costs a GPT-5 agent an average of $1.22 to exhaustively scan a live smart contract for profitable vulnerabilities. That was five months ago. The cost has continued falling since.
What the Research Actually Measured
The benchmark is called SCONE-bench. It was built from 405 real contracts that were actually exploited between 2020 and 2025, sourced from the DefiHackLabs repository. Not simulated vulnerabilities. Real ones, with documented on-chain losses, tested inside Docker-sandboxed blockchain forks to produce exact dollar figures.
Across all 405 contracts, 10 frontier models collectively produced working exploits for 207 of them - 51.11% - yielding $550.1 million in simulated stolen funds.
To control for data contamination, the researchers isolated contracts that were exploited after each model’s knowledge cutoff. Claude Opus 4.5, Sonnet 4.5, and GPT-5 collectively cracked 55.8% of those, corresponding to $4.6 million in simulated exploit revenue. Claude Opus 4.5 alone successfully exploited 65% of its post-cutoff set, extracting $3.7 million in simulation.
One year earlier, AI agents were exploiting roughly 2% of the same category of vulnerabilities. The jump from 2% to 55.8% happened in twelve months.
The Number That Should Change How You Think About Deployment
Here is the economics, drawn from the GPT-5 agent run on 2,849 recently deployed contracts with no known vulnerabilities:
- Total cost to scan all 2,849 contracts: $3,476
- Average cost per contract scan: $1.22
- Average cost per vulnerable contract identified: $1,738
- Average revenue per exploit found: $1,847
- Average net profit per vulnerable contract: $109
At $109 net profit on average, most individual finds are not yet wildly lucrative for an attacker. That changes the moment the agent is pointed at a contract holding meaningful liquidity. The Balancer exploit referenced in the paper involved $120 million. The cost to scan does not scale with the value held.
The researchers also tracked token efficiency across four generations of Claude models. The median token count required to produce a successful exploit dropped 70.2%. An attacker today gets roughly 3.4x more successful exploits per dollar of compute than they could six months ago. That ratio keeps moving.
The Two Zero-Days That Prove This Is Not Theoretical
The retrospective benchmark is striking. The forward-looking experiment is the part nobody in the DeFi space has absorbed correctly.
Both the Sonnet 4.5 and GPT-5 agents were pointed at 2,849 freshly deployed contracts with no known vulnerabilities. Best@1 - one attempt each. Both agents independently found two novel zero-day vulnerabilities worth $3,694 in simulated revenue.
The first was a missing view modifier on a public calculator function. The
function was designed to let users estimate rewards. Without the modifier,
it had write access by default. The agent called it 300 times in a loop,
inflated its token balance to the maximum profitable level, and sold back
to the decentralized exchange for native assets. The potential yield at peak
liquidity was $19,000. One developer oversight. One public function. One
loop.
The second was a missing fee recipient validation in a token launchpad contract. When no beneficiary was set, any caller could supply an arbitrary address and withdraw accumulated trading fees. The agent discovered it and flagged it for responsible disclosure. Four days later, an independent attacker found the same vulnerability and drained it.
The researchers tried to alert the developers in both cases. They could not reach them. Anonymous deployment is the default in DeFi. There is no notification infrastructure that matches the speed of an agent scanning contracts at $1.22 each.
The Capability Doubling Rate Nobody Is Taking Seriously
Across the post-knowledge-cutoff portion of the benchmark, frontier model exploit revenue doubled roughly every 1.3 months through 2025.
The researchers flag that this trend will plateau eventually. That is true. It is also the wrong thing to focus on right now, because the plateau has not arrived and the compounding is still running. By the time this post is published, the December 2025 figures are the floor, not the ceiling.
The benchmark also surfaced a meaningful difference between attack success rate and dollar extraction per exploit. GPT-5 and Opus 4.5 both “solved” the same benchmark problem. GPT-5 extracted $1.12 million. Opus 4.5 extracted $3.5 million from the same vulnerability - by systematically identifying and draining every liquidity pool and token contract that shared the same vulnerable pattern, not just the first one it found.
This is not a precision gap. It is a strategic gap. The more capable models are not just finding vulnerabilities faster. They are monetizing them more completely. That distinction matters for anyone thinking about what a real-world attacker with access to frontier models can do with thirty minutes and an API key.
What This Means for Anyone Building or Auditing Contracts
The traditional audit model - ship contract, hire a firm, get a PDF, deploy
- was already under strain before this research. It is now clearly insufficient on its own.
The audit window is closing. As agent costs fall and capabilities improve, the gap between contract deployment and first exploitation attempt will shrink toward zero. The researchers are direct about this: defenders need to adopt the same tools attackers now have access to.
The benchmark ships with a plug-and-play audit mode. You can run the same agent that found the zero-days against your own contracts in a sandboxed environment before you deploy. That capability exists today. Most teams building on-chain are not using it.
A few concrete moves if you are shipping contracts:
- Run automated agent-based auditing before deployment, not as a replacement for manual audit but as a first pass that catches the class of vulnerabilities these agents reliably find: access control gaps, missing modifiers, boundary conditions, and reentrancy variants.
- Assume your source code is readable. Verified source on BscScan is table stakes for any contract that wants to be traded. It also means every agent scanner in the world can read your code. Security through obscurity is not available to you.
- Do not deploy anonymously if you want to be reachable for responsible disclosure. Both zero-days in this research could not be responsibly disclosed because the developers left no contact path. The second one was drained by a third party four days later.
- Treat the $1.22 figure as your adversary’s operating cost. If your contract holds more than that in extractable value, the scan is already economically rational for an attacker to run. At $1,738 per identified vulnerability, any contract holding over a few thousand dollars in liquidity is inside the profitable range.
The same capabilities that find vulnerabilities can patch them. The researchers make that point explicitly. The offensive and defensive tools are the same tools. The question is which side runs them first.
Sources:
Written by Nirav Joshi · Fullstack and Blockchain Developer
Newsletter
Want the next post like this?
Subscribe for occasional emails when I publish something worth your time.