Claude Code Charges You and Won't Tell You Why. The Community Fixed It
Claude Code logs everything but surfaces nothing. Three developers built the observability layer the paid product never shipped - and what they found will change how you structure your prompting.
Anthropic built the best AI coding agent available right now. That’s not a controversial take - Claude Code is genuinely good, and developers who use it seriously know it.
They also know the other thing: it’s a black box with a billing meter attached.
You prompt, Claude works, tokens disappear. When the limit hits, you get a wall. No breakdown. No explanation. No way to know if you spent those tokens on productive work or on a 237-line CLAUDE.md being re-read on every single tool call.
That second scenario is real. Someone ran diagnostics on their own session data and found exactly that. One project. One session. 6,738% CLAUDE.md re-read cost overhead. More tokens spent on instructions than on actual work.
They weren’t doing anything obviously wrong. They’d just let their CLAUDE.md grow the way everyone’s does - tone guidelines here, a rule about migration files there, some documentation copied in for context. Standard practice. Quietly expensive.
And none of it was visible. The product didn’t surface it. The token counter just said: limit hit.
The Problem Anthropic Didn’t Ship a Solution For
Claude Code stores everything. Every session gets written as JSONL to ~/.claude/projects. Every tool call, every token count, every model used, every retry - it’s all there on disk.
Anthropic built the logging. They didn’t build the read layer.
So you’re paying for a product that generates rich diagnostic data about its own behavior and gives you no interface to read it. The gap isn’t technical - the data exists. The gap is that nobody at Anthropic shipped the tooling to surface it before they shipped the billing.
That’s not an accident exactly. It’s a prioritization decision. Ship the agent, instrument the cost recovery, figure out the observability layer later. The problem is that “later” has a cost. And right now developers are paying it.
In late March, Anthropic pushed v2.1.105 to address compute overuse. Users on $200/month Max plans started hitting limits in 19 minutes. Caching bugs were silently inflating costs 10–20x in the background. The fix broke authentication as a side effect. The thread on Reddit moved fast. The frustration was real - not because the bugs were unforgivable, but because developers had no tools to see what was happening to their quota even as it drained.
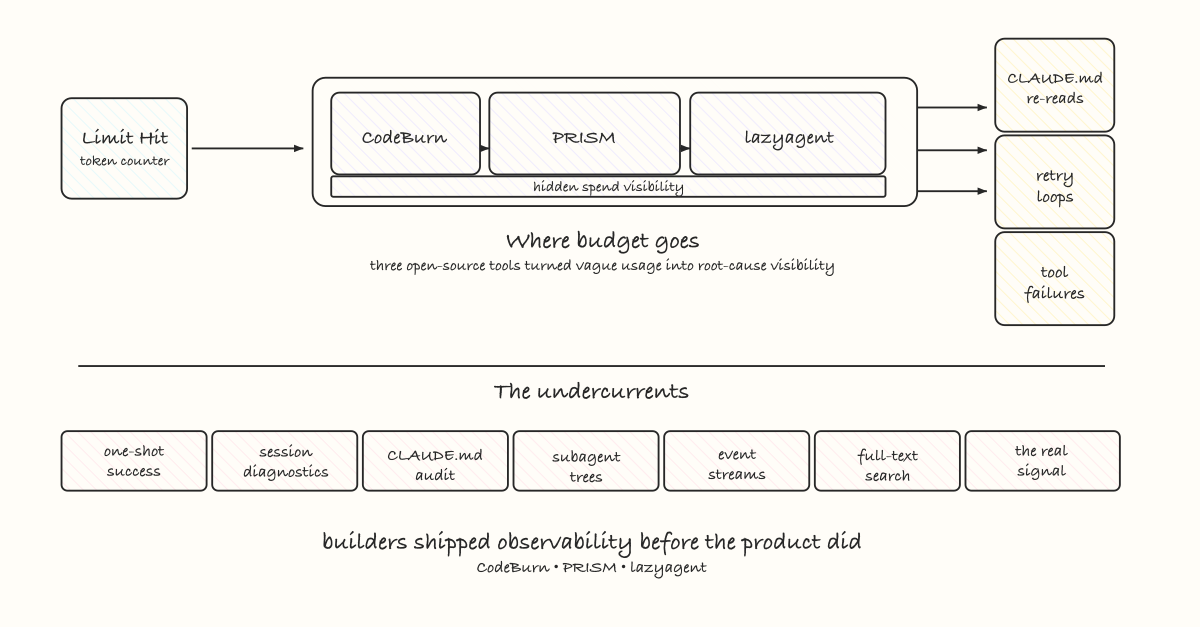
Three open-source tools shipped to fix that. Each one attacking a different part of the same problem.
CodeBurn: Where Did the Money Go
CodeBurn does the straightforward thing first: it reads those JSONL files and gives you a breakdown.
Cost by task type. Cost by model. Cost by project. Daily spend chart. And one metric that nothing else was tracking: one-shot success rate per activity.
This number matters more than it sounds. It answers the question you can’t answer by looking at cost alone - is the AI actually working, or is it burning tokens on retry loops?
Coding at 90% means Claude got it right first try nine out of ten times. Debugging at 40% means you’re spending a lot of tokens on failed attempts before the edit that sticks. That gap tells you something about where to focus your prompting, your CLAUDE.md rules, and your task structure.
CodeBurn classifies sessions into 13 categories - Coding, Debugging, Feature Dev, Refactoring, Testing, Exploration, Planning, Delegation, Git Ops, Build/Deploy, Brainstorming, Conversation, General - all determined by tool usage patterns and message keywords. No LLM calls. Fully deterministic. The classification itself is a small thing that changes how you think about your sessions as a portfolio of work rather than an undifferentiated token burn.
Install it with:
npx codeburnIt reads data Claude Code already wrote. Zero configuration.
PRISM: Why Are the Tokens Disappearing
If CodeBurn tells you how much you spent, PRISM tells you why.
The CLAUDE.md re-read problem is structural and most developers don’t know it exists. Every tool call Claude Code makes re-reads your CLAUDE.md from the top of context. A 200-line file times 50 tool calls is 10,000 tokens spent on instructions per session - before Claude writes a single line of code.
Most CLAUDE.md files grow without discipline. A rule about component structure. A tone guideline that made sense at the time. Documentation copied in because it was convenient. Rules that only apply to one subdirectory loaded globally. After a few months of active use, the file is doing three times the work it needs to and costing tokens on every call.
PRISM measures this exactly. It surfaces the overhead percentage per session, flags which lines are the primary drain, and tells you what to cut - with specific line numbers and the reason each line is costing more than it’s worth.
It also does something harder: it checks whether your rules are actually being followed. This is the part that should make you uncomfortable. PRISM found 4 migration file edits in a project with a rule explicitly saying never to touch them. Claude read the rule, acknowledged it, and then ignored it mid-session. That’s not a one-off - context degradation is real, and PRISM surfaces it systematically rather than making you notice by accident.
The grading system gives each project a score across five dimensions: Token Efficiency, Tool Health, Context Hygiene, CLAUDE.md Adherence, Session Continuity. The advisor generates a concrete diff - not suggestions, not guidelines, exact lines to remove or restructure with the cost rationale attached.
Install it with:
pip install prism-ccThen run:
prism analyzeWhat you find will rewrite how you structure your CLAUDE.md.
lazyagent: What’s Happening Right Now
CodeBurn and PRISM are retrospective. lazyagent is live.
It hooks into Claude Code, Codex, and OpenCode via their event systems and gives you a real-time TUI: five panes, subagent hierarchy, full event stream with type filtering, full-text search across payloads, syntax-highlighted diffs and code blocks.
The subagent hierarchy is the feature that matters as agent workflows get more complex. When Claude spawns a subagent, you need to see which agent spawned which, what each one ran, and what happened next. Without that visibility, debugging a multi-agent session is pattern matching against log files - slow and incomplete.
lazyagent makes the agent hierarchy a first-class thing you can navigate. It also runs across runtimes because the problem isn’t specific to Claude Code - every AI coding agent has shipped without a standard observability layer. The category has a blind spot and lazyagent is building toward fixing it across all of them, not just one.
Install it with:
brew install --cask lazyagentThen run:
lazyagent init claudeto wire it into your existing Claude Code setup. Existing hooks are preserved.
The Real Signal
Three developers built the observability layer that should have shipped with the paid product.
Not as a criticism of those developers - the tools are genuinely good and worth using. As an observation about how this category is moving. The agent tooling space right now is: ship fast, bill immediately, instrument the revenue, figure out the developer experience layer as a follow-on. That’s a reasonable product strategy under competitive pressure. It also means the builders paying $100–200/month are operating blind in ways that cost real money.
The gap between what’s shipped and what builders actually need - that’s where work happens right now. CodeBurn, PRISM, and lazyagent are one cluster of that work. There are others. The pattern will keep repeating as the agent category matures and the tools catch up to the billing.
If you’re using Claude Code seriously, run all three. Not once - build it into how you work. prism analyze after heavy sessions. codeburn on a weekly basis. lazyagent when you’re running anything multi-agent.
The developers who understand their token spend are going to get dramatically more out of these tools than everyone running blind. That gap is only going to widen.
Written by Nirav Joshi · Fullstack and Blockchain Developer
Newsletter
Want the next post like this?
Subscribe for occasional emails when I publish something worth your time.