You Gave Your Agent 50 Tools. That's Why It Keeps Failing.
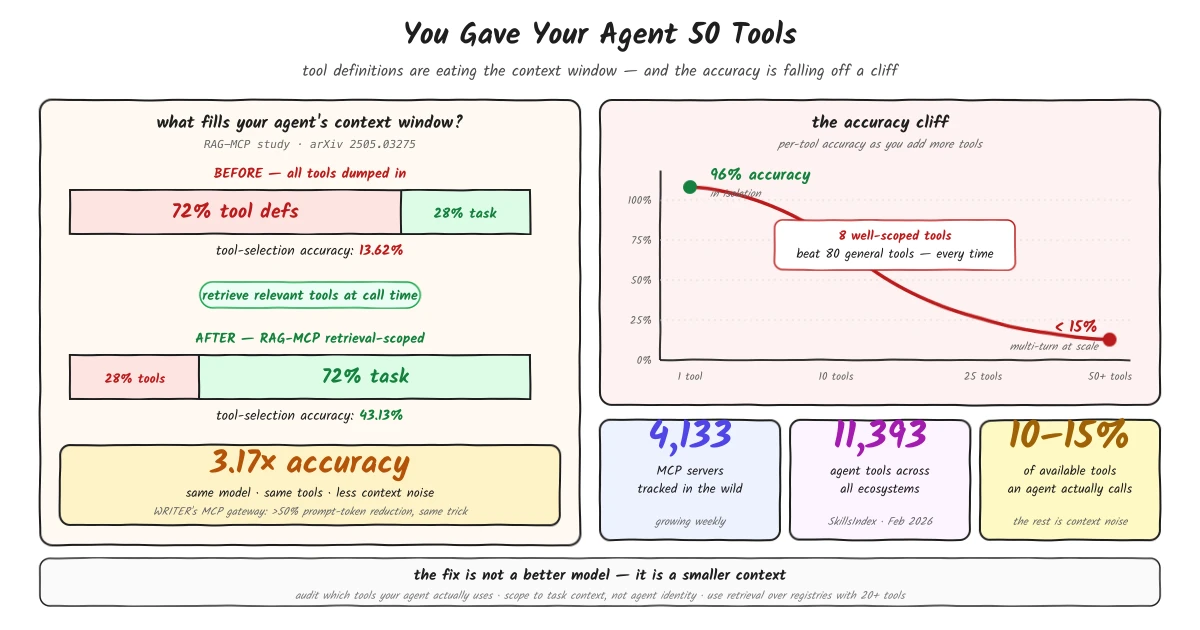
Tool definitions consume 72% of the context window before any work begins. Per-tool accuracy collapses from 96% in isolation to under 15% with a large toolset. Retrieval-scoped tools triple selection accuracy on the same model. The fix isn't a better model - it's a smaller context.
Most agent builders treat tool count as a capability metric. More tools, more things the agent can do. That intuition is wrong, and there is now a paper that quantifies exactly how wrong.
A 2025 study on RAG-MCP found that tool definitions consume 72% of an agent’s context window in typical MCP deployments before any actual work begins. Almost three-quarters of the model’s working memory spent on descriptions it will never touch on this particular turn. The same study replaced the all-tools- at-once approach with retrieval - showing the model only the tools relevant to the current query - and tool-selection accuracy went from 13.62% to 43.13%.
Same model. Same tools. More than triple the accuracy. The only change was how much of the model’s attention was spent on noise.
What Actually Breaks
The failure mode is not dramatic. The agent does not crash. It keeps running, keeps making tool calls, keeps returning results. It just gets progressively worse at doing the right thing with the right tool.
A team building an internal operations agent documented what happened when they loaded all 53 tools at once. Accuracy on their real workload collapsed immediately. The model hallucinated tool names that did not exist. It forgot user context halfway through a multi-step task and reached for customer-facing tools when the user was a distributor. It called the same tool twice with slightly different arguments and could not reconcile the different results.
The broader benchmark literature confirms the pattern at scale. Per-tool accuracy runs as high as 96% when a model is tested on a single tool in isolation. In large-toolset multi-turn settings, that figure collapses to under 15%. The degradation is not gradual - it is a cliff. A well-scoped agent with 8 tools that all apply to its task outperforms a general agent with 80 tools in almost every benchmark that tracks this.
The MCP ecosystem has made this worse faster than people expected. SkillsIndex now tracks 4,133 MCP servers in the wild, with the number growing weekly. The default developer move - “I need my agent to do more, I’ll add another MCP server” - is the exact pattern that drives the accuracy cliff. The tooling has scaled. The architecture that handles it has not.
Why the Standard Fix Does Not Work
The first instinct is to write better tool descriptions. Clearer names, more specific docstrings, better parameter explanations. This helps at the margins. It does not fix the structural problem.
Tool descriptions compete with the user’s message for the model’s attention. This is not a tuning issue. It is how the attention mechanism works. Every token the model processes costs attention weight. A context window loaded with tool definitions gives the model less attention capacity for the actual task. You cannot write your way out of that constraint.
The second instinct is to use a bigger context window. This also does not fix it. Atlan’s analysis of LLM context window limitations in 2026 found that multi-step agents compound the problem with every tool call - results get appended back into context, token counts climb, and earlier task details fall out of the active window by step 25. A 1M context window does not solve attention dilution. It just delays the cliff.
The Architecture That Actually Works
The answer is retrieval, not configuration. Do not give the agent all tools. Give it the tools relevant to the current query, dynamically, at call time.
This is what the RAG-MCP approach implements. Instead of dumping every tool definition into the prompt at the start, a retrieval layer sits between the agent and the tool registry. When a query arrives, the retrieval layer finds the relevant tools - based on semantic similarity to the query - and passes only those into the model’s context. The model sees 6 tools instead of 60. It uses 28% of its context window on tool definitions instead of 72%.
WRITER’s MCP Gateway implementation takes this further. It ingests APIs via OpenAPI specs, rewrites tool descriptions automatically for LLM clarity, and applies vector-based retrieval to reduce hundreds of granular endpoints into a small set of relevant tools per request. They report more than a 50% reduction in prompt tokens alongside the accuracy improvements.
The team that solved their 53-tool problem used context-scoped tool loading: a middleware layer that intercepts MCP tool list requests and filters them based on the current conversation state. When the user is in a distributor flow, the agent sees distributor tools. When the user is in a customer flow, it sees customer tools. The filtering happens in code before the model touches the context. The model’s accuracy in their workload climbed back to useful levels without changing the model or the underlying tools at all.
What This Means If You Are Building on MCP
The MCP ecosystem is growing fast enough that this is already a production problem, not a future consideration. 4,133 MCP servers. 11,393 agent tools across all ecosystems tracked by SkillsIndex, up from a handful eighteen months ago. Most of those tools have no scoping, no retrieval layer, and no concept of what happens when a model tries to hold all of them in memory simultaneously.
The builders treating MCP as an additive system - add a server, unlock a capability - are building toward the accuracy cliff. The builders who will have working agents at scale are the ones who treat tool delivery as an architecture problem, not a configuration problem.
Three things to change before you add another MCP server:
- Audit what your agent actually uses. Log which tools get called across real workloads. Most agents use 10-15% of the tools available to them consistently. The rest is noise in the context window.
- Scope tools to task context, not agent identity. The agent does not need all its tools on every turn. Build a middleware layer that filters the tool list based on current conversation state. This is a few lines of code and it directly addresses attention dilution.
- Use retrieval for large tool registries. If you have more than 20 tools, implement semantic retrieval over the tool registry instead of passing everything to the model. The RAG-MCP paper is public. The accuracy improvement is not marginal - it is the difference between an agent that works and one that looks like it works in demos.
The 13.62% to 43.13% accuracy jump came from removing noise, not from adding capability. Most agents right now are sitting somewhere in the 13% range wondering why they keep failing. The fix is not a better model. It is a smaller context.
Sources:
- RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation, Gan & Sun (arXiv 2505.03275)
- Scaling an AI Agent to 53 Tools Without Making It Dumber, dev.to
- When Too Many Tools Become Too Much Context, WRITER Engineering
- State of AI Agent Tools 2026: 11,393 Tools Analyzed, SkillsIndex
- LLM Context Window Limitations in 2026, Atlan
- Model Overload: Why Too Many Tools Harm LLM Performance, LinkedIn via Hack Team
Written by Nirav Joshi · Fullstack and Blockchain Developer
Newsletter
Want the next post like this?
Subscribe for occasional emails when I publish something worth your time.