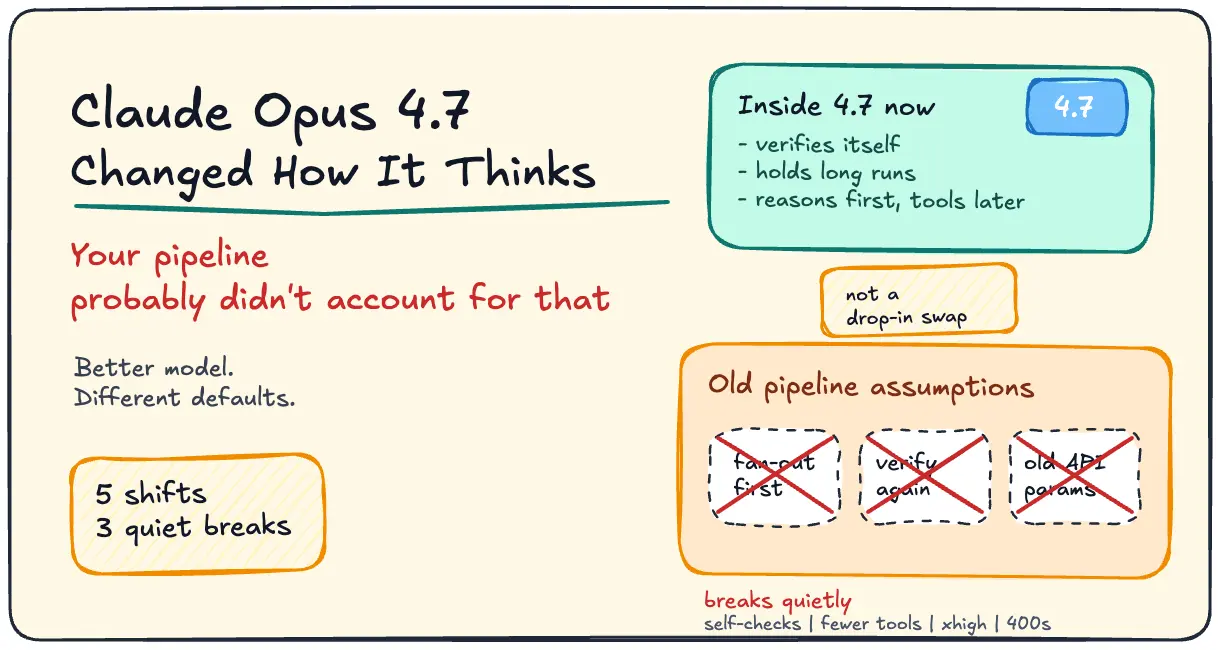
Claude Opus 4.7 Changed How It Thinks. Your Pipeline Probably Didn't Account For That.
Opus 4.7's benchmarks are real, but five behavioral shifts and three hard API breaks will silently degrade pipelines tuned for 4.6. Here's what actually changed and what to fix.
The benchmarks look good. The blog posts are out. Everyone’s talking about what 4.7 can do.
Nobody’s talking about what breaks.
I spent time going through the actual behavioral changes, not the announcements, the specifics. Five things shifted. Three of them will silently break production pipelines that worked fine on 4.6. Here’s what actually changed and what you need to do about it.
It Verifies Itself Now. You Didn’t Ask For It.
The most underreported change: 4.7 checks its own assumptions mid-task before acting. Not when prompted. By default.
Rakuten tested this on production SWE-bench tasks. Resolution rate tripled. That’s not a minor bump. That’s a fundamental shift in where the model spends its compute before returning output.
The implication: tasks that previously required you to build verification loops around the model now need to be redesigned. 4.7 is doing some of that work internally. If your pipeline adds an external check on top of it, you’re doubling the verification cost without doubling the value. Audit that before you assume the old architecture still makes sense.
Long-Run Coherence Is Real Now
Genspark measured Claude 4.6 looping indefinitely on 1 in every 18 queries during extended runs. 4.7 brought that near zero.
Devin reports it holds context coherently over hours. Not sessions, hours of continuous work.
If you’re building agentic systems, this changes the calculus on how long you let a run go before forcing a checkpoint. The previous answer was “checkpoint aggressively because the model drifts.” The new answer is less obvious. Start running your own measurements. Don’t inherit someone else’s checkpoint frequency from a 4.6 integration.
It Reasons More and Tools Less. That Breaks Fan-Out Architectures.
This one is the silent killer.
4.6 would fan out to subagents aggressively. Many pipelines were designed around that: parallel tool calls, wide exploration, then synthesis. 4.7 flipped the default: it reasons first, reaches for tools later.
If your system prompt was tuned around 4.6’s behavior, expecting aggressive exploration, you’re getting a different model inside the same API. It won’t error. It’ll just behave differently than you designed for, and you’ll spend time debugging what looks like a reasoning failure but is actually a behavioral mismatch.
Audit your prompts for anything that implicitly relies on tool-first behavior. If you built around the old defaults, rebuild around the new ones.
There’s a New Effort Tier and It Changes Your Cost Math
Anthropic added xhigh, sitting between high and max. Claude Code raised its default to xhigh when 4.7 shipped.
The Hex team put it clearly: low-effort Opus 4.7 performs roughly at the level of medium-effort Opus 4.6. That’s useful in both directions. You might be over-spending on effort settings you inherited. You might be under-spending and blaming the model.
The practical move: re-benchmark your specific tasks at each effort level. Don’t assume the old effort tuning transfers.
Vision Resolution Tripled. So Did the Token Cost.
Input resolution jumped from 1568px to 2576px. For dense diagrams, design mockups, and coordinate-heavy tasks, the gap in output quality is real.
The cost you’re not seeing in the announcement: a full-res image now burns roughly 4,784 tokens. At 1568px it was around 1,600. That’s 3x the token count for the same image.
If you’re processing images at volume, that’s not a footnote. It’s a budget line item. Check whether your use case actually needs the full resolution or whether you’re just inheriting a default setting.
Three API Changes That Return 400s
These aren’t behavioral shifts. They’re hard breaks.
1. Thinking syntax changed.
thinking: {type: "enabled"} returns a 400 error. Switch to type: "adaptive" with an explicit effort level.
// Before (breaks on 4.7)
{
"thinking": { "type": "enabled" }
}
// After
{
"thinking": { "type": "adaptive", "effort": "xhigh" }
}2. Sampling params are locked.
temperature, top_p, and top_k return 400 if set to anything other than their defaults. If you have these in your calls, and most integrations do, strip them now.
3. New tokenizer, higher counts.
The same input can produce up to 1.35x the token count it did on 4.6. Re-run your cost projections. Don’t wait until your first invoice.
What This Actually Means
4.7 is a better model. The Rakuten numbers are real. The loop elimination is real. The coherence over long runs is real.
But “better model” and “drop-in replacement” are not the same thing, and the announcement doesn’t separate them clearly. Most of what breaks is behavioral: the model doing more internally now, by default, in ways that assume your architecture isn’t also doing that work.
The integration tax is real. The people who read the full changelog and pressure-tested their pipelines in the first 48 hours already have an advantage over the people who took the benchmarks at face value and shipped.
That gap compounds. It always does.
Sources: Speedy Dev on agentic coding changes · 5 things to know · What changed for AI builders · Stackademic 48hr breakdown · API access guide
Written by Nirav Joshi · Fullstack and Blockchain Developer
Newsletter
Want the next post like this?
Subscribe for occasional emails when I publish something worth your time.